#Kubernetes Cluster
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
Load Balancing Web Sockets with K8s/Istio
When load balancing WebSockets in a Kubernetes (K8s) environment with Istio, there are several considerations to ensure persistent, low-latency connections. WebSockets require special handling because they are long-lived, bidirectional connections, which are different from standard HTTP request-response communication. Here’s a guide to implementing load balancing for WebSockets using Istio.
1. Enable WebSocket Support in Istio
By default, Istio supports WebSocket connections, but certain configurations may need tweaking. You should ensure that:
Destination rules and VirtualServices are configured appropriately to allow WebSocket traffic.
Example VirtualService Configuration.
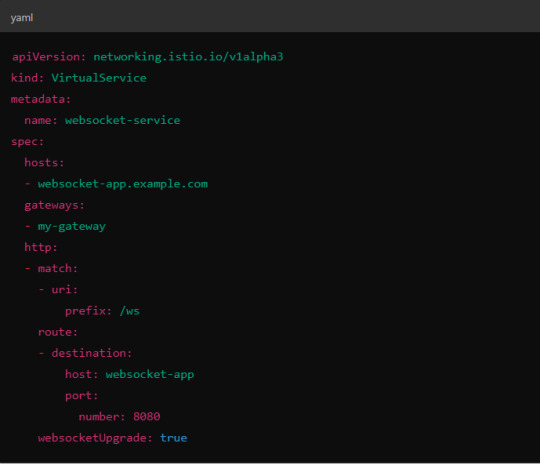
Here, websocketUpgrade: true explicitly allows WebSocket traffic and ensures that Istio won’t downgrade the WebSocket connection to HTTP.
2. Session Affinity (Sticky Sessions)
In WebSocket applications, sticky sessions or session affinity is often necessary to keep long-running WebSocket connections tied to the same backend pod. Without session affinity, WebSocket connections can be terminated if the load balancer routes the traffic to a different pod.
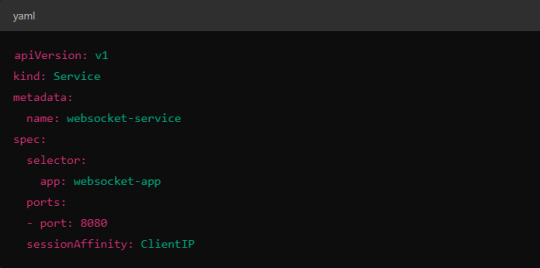
Implementing Session Affinity in Istio.
Session affinity is typically achieved by setting the sessionAffinity field to ClientIP at the Kubernetes service level.
In Istio, you might also control affinity using headers. For example, Istio can route traffic based on headers by configuring a VirtualService to ensure connections stay on the same backend.
3. Load Balancing Strategy
Since WebSocket connections are long-lived, round-robin or random load balancing strategies can lead to unbalanced workloads across pods. To address this, you may consider using least connection or consistent hashing algorithms to ensure that existing connections are efficiently distributed.
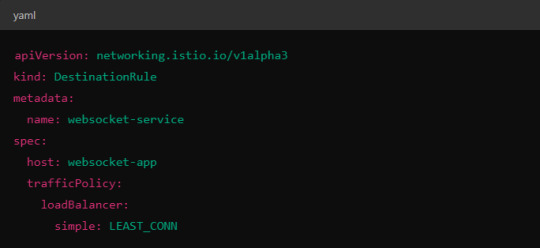
Load Balancer Configuration in Istio.
Istio allows you to specify different load balancing strategies in the DestinationRule for your services. For WebSockets, the LEAST_CONN strategy may be more appropriate.
Alternatively, you could use consistent hashing for a more sticky routing based on connection properties like the user session ID.
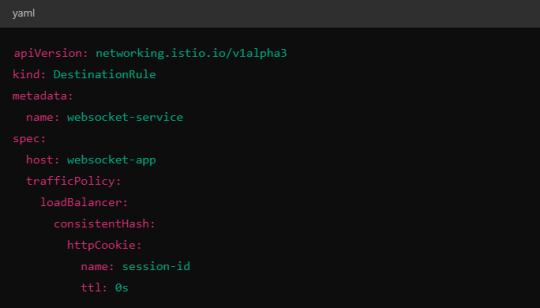
This configuration ensures that connections with the same session ID go to the same pod.
4. Scaling Considerations
WebSocket applications can handle a large number of concurrent connections, so you’ll need to ensure that your Kubernetes cluster can scale appropriately.
Horizontal Pod Autoscaler (HPA): Use an HPA to automatically scale your pods based on metrics like CPU, memory, or custom metrics such as open WebSocket connections.
Istio Autoscaler: You may also scale Istio itself to handle the increased load on the control plane as WebSocket connections increase.
5. Connection Timeouts and Keep-Alive
Ensure that both your WebSocket clients and the Istio proxy (Envoy) are configured for long-lived connections. Some settings that need attention:
Timeouts: In VirtualService, make sure there are no aggressive timeout settings that would prematurely close WebSocket connections.

Keep-Alive Settings: You can also adjust the keep-alive settings at the Envoy level if necessary. Envoy, the proxy used by Istio, supports long-lived WebSocket connections out-of-the-box, but custom keep-alive policies can be configured.
6. Ingress Gateway Configuration
If you're using an Istio Ingress Gateway, ensure that it is configured to handle WebSocket traffic. The gateway should allow for WebSocket connections on the relevant port.
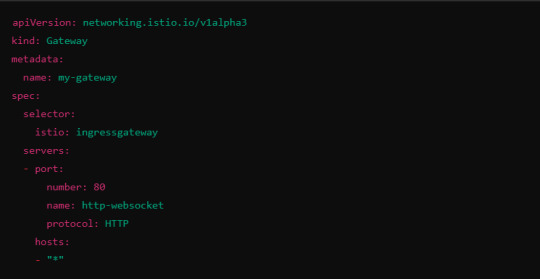
This configuration ensures that the Ingress Gateway can handle WebSocket upgrades and correctly route them to the backend service.
Summary of Key Steps
Enable WebSocket support in Istio’s VirtualService.
Use session affinity to tie WebSocket connections to the same backend pod.
Choose an appropriate load balancing strategy, such as least connection or consistent hashing.
Set timeouts and keep-alive policies to ensure long-lived WebSocket connections.
Configure the Ingress Gateway to handle WebSocket traffic.
By properly configuring Istio, Kubernetes, and your WebSocket service, you can efficiently load balance WebSocket connections in a microservices architecture.
#kubernetes#websockets#Load Balancing#devops#linux#coding#programming#Istio#virtualservices#Load Balancer#Kubernetes cluster#gateway#python#devlog#github#ansible
5 notes
·
View notes
Text
Helm Tutorials— Simplify Kubernetes Package Handling | Waytoeasylearn
Helm is a tool designed to simplify managing applications on Kubernetes. It makes installing, updating, and sharing software on cloud servers easier. This article explains what Helm is, how it functions, and why many people prefer it. It highlights its key features and shows how it can improve your workflow.
Master Helm Effortlessly! 🚀 Dive into the Best Waytoeasylearn Tutorials for Streamlined Kubernetes & Cloud Deployments.➡️ Learn Now!

What You Will Learn
✔ What Helm Is — Understand why Helm is important for Kubernetes and what its main parts are. ✔ Helm Charts & Templates — Learn to create and modify Helm charts using templates, variables, and built-in features. ✔ Managing Repositories — Set up repositories, host your charts, and track different versions with ChartMuseum. ✔ Handling Charts & Dependencies — Perform upgrades, rollbacks, and manage dependencies easily. ✔ Helm Hooks & Kubernetes Jobs — Use hooks to run tasks before or after installation and updates. ✔ Testing & Validation — Check Helm charts through linting, status checks, and organized tests.
Why Take This Course?
🚀 Simplifies Kubernetes Workflows — Automate the process of deploying applications with Helm. 💡 Hands-On Learning — Use real-world examples and case studies to see how Helm works. ⚡ Better Management of Charts & Repositories — Follow best practices for organizing and handling charts and repositories.
After this course, you will be able to manage Kubernetes applications more efficiently using Helm’s tools for automation and packaging.
0 notes
Text
#kubernetes cluster setup#kubernetes etcd cluster setup#master node#kubernetes cluster#kubernetes#kubernetes architecture
0 notes
Text
spoilerfree (snes/trailer content only) super mario rpg remake impressions because i just did the entire thing in one sitting because it leaked and it's in my top five ever:
difficulty is way lower than the original, play whatever weird team comp you want, the mario/peach/ meta is dead. also mallow actually does damage now! it's a christmas miracle
outside combat it's probably the most faithful remake i've seen in decades for better or worse, it's about 95% the same as the original which isn't a bad thing at all, it's even got Ted Woolsey's script with minimal changes
some of the new remixes are absolute bangers but one very specific important one sucks intensely compared to the original, you'll know it when you hear it
the combat changes are a mixed bag and the team supermoves are very, very powerful. Run mario/bowser/geno and you basically handicap every boss
it's very difficult to fall behind in flower points, there seem to be way more flowers around than in the original so you aren't handicapping yourself if you screw up booster hill or midas falls the first time
status effects (especially bowser's Fear spell) are way more effective than they used to be
THEY RENAMED MACK TO A THROCKMORTON JOKE. WHY
there is postgame (complete with saving a clear file and reloading after smithy) but i'm not playing it until my physical copy shows up since I rushed through this on a switch that isn't mine
everything you'd think they'd remove for censorship reasons is still there.. except for mario's peace sign, which is gone and makes the scene where he talks to monstermama and conveys 'piece' with a peace sign very confusing
booster's crying animation is absolutely incredible in 3D tl;dr : if you haven't played SMRPG previously this is a great adaptation and does right by the original, if you have you might be slightly disoriented but you're still going to have a good time.
#super mario rpg#i permanently have smrpgr associated with provisioning Kubernetes because i was migrating systems to a cluster all day while playing it#i hope the physical cart comes with a printed manual like japan's getting; the OG manual was great and written entirely by luigi iirc
4 notes
·
View notes
Text
well, i was going to work out tonight but then i laid on my bed and now it's 11:30. it's not any later than i've worked out in the past lol but i really want to get an actual good night's sleep tonight and won't be able to if i workout now bc that means bed at 1am earliest.
#i did finally figure out how to fucking deploy something to a kubernetes cluster via helm so#that was a productive evening#been fighting this battle for like a month i swear
1 note
·
View note
Text
Simplifying Hybrid Cloud Management with Red Hat Advanced Cluster Management for Kubernetes
In today's dynamic IT landscape, organizations are increasingly adopting hybrid and multi-cloud strategies to achieve greater flexibility, scalability, and resilience. However, managing Kubernetes clusters across diverse environments—on-premises data centers, public clouds, and edge locations—presents significant challenges. This complexity can lead to operational overhead, security vulnerabilities, and inconsistent application deployments. This is where Red Hat Advanced Cluster Management for Kubernetes (ACM) steps in, offering a centralized and streamlined approach to hybrid cloud management.
The Challenges of Hybrid Cloud Kubernetes Management:
Managing multiple Kubernetes clusters in a hybrid cloud environment can quickly become overwhelming. Some key challenges include:
Inconsistent Configurations: Maintaining consistent configurations across different clusters can be difficult, leading to inconsistencies in application deployments and potential security risks.
Visibility and Control: Gaining a unified view of all clusters and their health can be challenging, hindering effective monitoring and troubleshooting.
Security and Compliance: Enforcing consistent security policies and ensuring compliance across all environments can be complex and time-consuming.
Application Lifecycle Management: Deploying, updating, and managing applications across multiple clusters can be cumbersome and error-prone.
How Red Hat Advanced Cluster Management Simplifies Hybrid Cloud Management:
Red Hat ACM provides a comprehensive solution for managing the entire lifecycle of Kubernetes clusters across hybrid and multi-cloud environments. It offers several key features that simplify management and improve operational efficiency:
Centralized Management: ACM provides a single console for managing all your Kubernetes clusters, regardless of where they are deployed. This centralized view simplifies operations and provides consistent control.
Policy-Based Governance: ACM allows you to define and enforce consistent policies across all your clusters, ensuring compliance with security and regulatory requirements.
Application Lifecycle Management: ACM simplifies the deployment, updating, and management of applications across multiple clusters, streamlining the application lifecycle.
Cluster Lifecycle Management: ACM streamlines the creation, scaling, and deletion of Kubernetes clusters, simplifying infrastructure management.
Observability and Monitoring: ACM provides comprehensive monitoring and observability capabilities, giving you insights into the health and performance of your clusters and applications.
GitOps Integration: ACM integrates with GitOps workflows, enabling declarative infrastructure and application management for improved automation and consistency.
Key Benefits of Using Red Hat Advanced Cluster Management:
Reduced Operational Overhead: By centralizing management and automating key tasks, ACM reduces the operational burden on IT teams.
Improved Security and Compliance: Policy-based governance ensures consistent security and compliance across all environments.
Faster Application Deployments: Streamlined application lifecycle management accelerates time to market for new applications.
Increased Agility and Flexibility: ACM enables organizations to quickly adapt to changing business needs by easily managing and scaling their Kubernetes infrastructure.
Enhanced Visibility and Control: Centralized monitoring and observability provide a clear view of the health and performance of all clusters and applications.
Use Cases for Red Hat Advanced Cluster Management:
Hybrid Cloud Deployments: Managing Kubernetes clusters across on-premises data centers and public clouds.
Multi-Cloud Deployments: Managing Kubernetes clusters across multiple public cloud providers.
Edge Computing: Managing Kubernetes clusters deployed at the edge of the network.
DevOps and CI/CD: Automating the deployment and management of applications in a CI/CD pipeline.
Conclusion:
Red Hat Advanced Cluster Management for Kubernetes is a powerful tool for simplifying the complexities of hybrid cloud Kubernetes management. By providing centralized management, policy-based governance, and automated workflows, ACM empowers organizations to effectively manage their Kubernetes infrastructure and accelerate their cloud-native journey. If you're struggling to manage your Kubernetes clusters across multiple environments, Red Hat ACM is a solution worth exploring.
Ready to simplify your hybrid cloud Kubernetes management?
Contact Hawkstack Technologies today to learn more about Red Hat Advanced Cluster Management and how we can help you implement it in your environment. www.hawkstack.com
1 note
·
View note
Video
youtube
Step-by-Step Guide: Configuring a Kubernetes Cluster on AWS EC2
#youtube#kubernetes k8s ec2 awsdevops aws cloudcomputing cluster devops devopsengineer t2medium infrastructure kubernetesfullcourse kubeadm
0 notes
Text
Deploying Large Language Models on Kubernetes: A Comprehensive Guide
New Post has been published on https://thedigitalinsider.com/deploying-large-language-models-on-kubernetes-a-comprehensive-guide/
Deploying Large Language Models on Kubernetes: A Comprehensive Guide
Large Language Models (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation.
However, deploying LLMs can be a challenging task due to their immense size and computational requirements. Kubernetes, an open-source container orchestration system, provides a powerful solution for deploying and managing LLMs at scale. In this technical blog, we’ll explore the process of deploying LLMs on Kubernetes, covering various aspects such as containerization, resource allocation, and scalability.
Understanding Large Language Models
Before diving into the deployment process, let’s briefly understand what Large Language Models are and why they are gaining so much attention.
Large Language Models (LLMs) are a type of neural network model trained on vast amounts of text data. These models learn to understand and generate human-like language by analyzing patterns and relationships within the training data. Some popular examples of LLMs include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), and XLNet.
LLMs have achieved remarkable performance in various NLP tasks, such as text generation, language translation, and question answering. However, their massive size and computational requirements pose significant challenges for deployment and inference.
Why Kubernetes for LLM Deployment?
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It provides several benefits for deploying LLMs, including:
Scalability: Kubernetes allows you to scale your LLM deployment horizontally by adding or removing compute resources as needed, ensuring optimal resource utilization and performance.
Resource Management: Kubernetes enables efficient resource allocation and isolation, ensuring that your LLM deployment has access to the required compute, memory, and GPU resources.
High Availability: Kubernetes provides built-in mechanisms for self-healing, automatic rollouts, and rollbacks, ensuring that your LLM deployment remains highly available and resilient to failures.
Portability: Containerized LLM deployments can be easily moved between different environments, such as on-premises data centers or cloud platforms, without the need for extensive reconfiguration.
Ecosystem and Community Support: Kubernetes has a large and active community, providing a wealth of tools, libraries, and resources for deploying and managing complex applications like LLMs.
Preparing for LLM Deployment on Kubernetes:
Before deploying an LLM on Kubernetes, there are several prerequisites to consider:
Kubernetes Cluster: You’ll need a Kubernetes cluster set up and running, either on-premises or on a cloud platform like Amazon Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE), or Azure Kubernetes Service (AKS).
GPU Support: LLMs are computationally intensive and often require GPU acceleration for efficient inference. Ensure that your Kubernetes cluster has access to GPU resources, either through physical GPUs or cloud-based GPU instances.
Container Registry: You’ll need a container registry to store your LLM Docker images. Popular options include Docker Hub, Amazon Elastic Container Registry (ECR), Google Container Registry (GCR), or Azure Container Registry (ACR).
LLM Model Files: Obtain the pre-trained LLM model files (weights, configuration, and tokenizer) from the respective source or train your own model.
Containerization: Containerize your LLM application using Docker or a similar container runtime. This involves creating a Dockerfile that packages your LLM code, dependencies, and model files into a Docker image.
Deploying an LLM on Kubernetes
Once you have the prerequisites in place, you can proceed with deploying your LLM on Kubernetes. The deployment process typically involves the following steps:
Building the Docker Image
Build the Docker image for your LLM application using the provided Dockerfile and push it to your container registry.
Creating Kubernetes Resources
Define the Kubernetes resources required for your LLM deployment, such as Deployments, Services, ConfigMaps, and Secrets. These resources are typically defined using YAML or JSON manifests.
Configuring Resource Requirements
Specify the resource requirements for your LLM deployment, including CPU, memory, and GPU resources. This ensures that your deployment has access to the necessary compute resources for efficient inference.
Deploying to Kubernetes
Use the kubectl command-line tool or a Kubernetes management tool (e.g., Kubernetes Dashboard, Rancher, or Lens) to apply the Kubernetes manifests and deploy your LLM application.
Monitoring and Scaling
Monitor the performance and resource utilization of your LLM deployment using Kubernetes monitoring tools like Prometheus and Grafana. Adjust the resource allocation or scale your deployment as needed to meet the demand.
Example Deployment
Let’s consider an example of deploying the GPT-3 language model on Kubernetes using a pre-built Docker image from Hugging Face. We’ll assume that you have a Kubernetes cluster set up and configured with GPU support.
Pull the Docker Image:
bashCopydocker pull huggingface/text-generation-inference:1.1.0
Create a Kubernetes Deployment:
Create a file named gpt3-deployment.yaml with the following content:
apiVersion: apps/v1 kind: Deployment metadata: name: gpt3-deployment spec: replicas: 1 selector: matchLabels: app: gpt3 template: metadata: labels: app: gpt3 spec: containers: - name: gpt3 image: huggingface/text-generation-inference:1.1.0 resources: limits: nvidia.com/gpu: 1 env: - name: MODEL_ID value: gpt2 - name: NUM_SHARD value: "1" - name: PORT value: "8080" - name: QUANTIZE value: bitsandbytes-nf4
This deployment specifies that we want to run one replica of the gpt3 container using the huggingface/text-generation-inference:1.1.0 Docker image. The deployment also sets the environment variables required for the container to load the GPT-3 model and configure the inference server.
Create a Kubernetes Service:
Create a file named gpt3-service.yaml with the following content:
apiVersion: v1 kind: Service metadata: name: gpt3-service spec: selector: app: gpt3 ports: - port: 80 targetPort: 8080 type: LoadBalancer
This service exposes the gpt3 deployment on port 80 and creates a LoadBalancer type service to make the inference server accessible from outside the Kubernetes cluster.
Deploy to Kubernetes:
Apply the Kubernetes manifests using the kubectl command:
kubectl apply -f gpt3-deployment.yaml kubectl apply -f gpt3-service.yaml
Monitor the Deployment:
Monitor the deployment progress using the following commands:
kubectl get pods kubectl logs <pod_name>
Once the pod is running and the logs indicate that the model is loaded and ready, you can obtain the external IP address of the LoadBalancer service:
kubectl get service gpt3-service
Test the Deployment:
You can now send requests to the inference server using the external IP address and port obtained from the previous step. For example, using curl:
curl -X POST http://<external_ip>:80/generate -H 'Content-Type: application/json' -d '"inputs": "The quick brown fox", "parameters": "max_new_tokens": 50'
This command sends a text generation request to the GPT-3 inference server, asking it to continue the prompt “The quick brown fox” for up to 50 additional tokens.
Advanced topics you should be aware of
While the example above demonstrates a basic deployment of an LLM on Kubernetes, there are several advanced topics and considerations to explore:
_*]:min-w-0″ readability=”131.72387362124″>
1. Autoscaling
Kubernetes supports horizontal and vertical autoscaling, which can be beneficial for LLM deployments due to their variable computational demands. Horizontal autoscaling allows you to automatically scale the number of replicas (pods) based on metrics like CPU or memory utilization. Vertical autoscaling, on the other hand, allows you to dynamically adjust the resource requests and limits for your containers.
To enable autoscaling, you can use the Kubernetes Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA). These components monitor your deployment and automatically scale resources based on predefined rules and thresholds.
2. GPU Scheduling and Sharing
In scenarios where multiple LLM deployments or other GPU-intensive workloads are running on the same Kubernetes cluster, efficient GPU scheduling and sharing become crucial. Kubernetes provides several mechanisms to ensure fair and efficient GPU utilization, such as GPU device plugins, node selectors, and resource limits.
You can also leverage advanced GPU scheduling techniques like NVIDIA Multi-Instance GPU (MIG) or AMD Memory Pool Remapping (MPR) to virtualize GPUs and share them among multiple workloads.
3. Model Parallelism and Sharding
Some LLMs, particularly those with billions or trillions of parameters, may not fit entirely into the memory of a single GPU or even a single node. In such cases, you can employ model parallelism and sharding techniques to distribute the model across multiple GPUs or nodes.
Model parallelism involves splitting the model architecture into different components (e.g., encoder, decoder) and distributing them across multiple devices. Sharding, on the other hand, involves partitioning the model parameters and distributing them across multiple devices or nodes.
Kubernetes provides mechanisms like StatefulSets and Custom Resource Definitions (CRDs) to manage and orchestrate distributed LLM deployments with model parallelism and sharding.
4. Fine-tuning and Continuous Learning
In many cases, pre-trained LLMs may need to be fine-tuned or continuously trained on domain-specific data to improve their performance for specific tasks or domains. Kubernetes can facilitate this process by providing a scalable and resilient platform for running fine-tuning or continuous learning workloads.
You can leverage Kubernetes batch processing frameworks like Apache Spark or Kubeflow to run distributed fine-tuning or training jobs on your LLM models. Additionally, you can integrate your fine-tuned or continuously trained models with your inference deployments using Kubernetes mechanisms like rolling updates or blue/green deployments.
5. Monitoring and Observability
Monitoring and observability are crucial aspects of any production deployment, including LLM deployments on Kubernetes. Kubernetes provides built-in monitoring solutions like Prometheus and integrations with popular observability platforms like Grafana, Elasticsearch, and Jaeger.
You can monitor various metrics related to your LLM deployments, such as CPU and memory utilization, GPU usage, inference latency, and throughput. Additionally, you can collect and analyze application-level logs and traces to gain insights into the behavior and performance of your LLM models.
6. Security and Compliance
Depending on your use case and the sensitivity of the data involved, you may need to consider security and compliance aspects when deploying LLMs on Kubernetes. Kubernetes provides several features and integrations to enhance security, such as network policies, role-based access control (RBAC), secrets management, and integration with external security solutions like HashiCorp Vault or AWS Secrets Manager.
Additionally, if you’re deploying LLMs in regulated industries or handling sensitive data, you may need to ensure compliance with relevant standards and regulations, such as GDPR, HIPAA, or PCI-DSS.
7. Multi-Cloud and Hybrid Deployments
While this blog post focuses on deploying LLMs on a single Kubernetes cluster, you may need to consider multi-cloud or hybrid deployments in some scenarios. Kubernetes provides a consistent platform for deploying and managing applications across different cloud providers and on-premises data centers.
You can leverage Kubernetes federation or multi-cluster management tools like KubeFed or GKE Hub to manage and orchestrate LLM deployments across multiple Kubernetes clusters spanning different cloud providers or hybrid environments.
These advanced topics highlight the flexibility and scalability of Kubernetes for deploying and managing LLMs.
Conclusion
Deploying Large Language Models (LLMs) on Kubernetes offers numerous benefits, including scalability, resource management, high availability, and portability. By following the steps outlined in this technical blog, you can containerize your LLM application, define the necessary Kubernetes resources, and deploy it to a Kubernetes cluster.
However, deploying LLMs on Kubernetes is just the first step. As your application grows and your requirements evolve, you may need to explore advanced topics such as autoscaling, GPU scheduling, model parallelism, fine-tuning, monitoring, security, and multi-cloud deployments.
Kubernetes provides a robust and extensible platform for deploying and managing LLMs, enabling you to build reliable, scalable, and secure applications.
#access control#Amazon#Amazon Elastic Kubernetes Service#amd#Apache#Apache Spark#app#applications#apps#architecture#Artificial Intelligence#attention#AWS#azure#Behavior#BERT#Blog#Blue#Building#chatbots#Cloud#cloud platform#cloud providers#cluster#clusters#code#command#Community#compliance#comprehensive
0 notes
Text
Install Canonical Kubernetes on Linux | Snap Store
Fast, secure & automated application deployment, everywhere Canonical Kubernetes is the fastest, easiest way to deploy a fully-conformant Kubernetes cluster. Harnessing pure upstream Kubernetes, this distribution adds the missing pieces (e.g. ingress, dns, networking) for a zero-ops experience. Get started in just two commands: sudo snap install k8s –classic sudo k8s bootstrap — Read on…
View On WordPress
#dns#easiest way to deploy a fully-conformant Kubernetes cluster. Harnessing pure upstream Kubernetes#everywhere Canonical Kubernetes is the fastest#Fast#networking) for a zero-ops experience. Get started in just two commands: sudo snap install k8s --classic sudo k8s bootstrap#secure & automated application deployment#this distribution adds the missing pieces (e.g. ingress
1 note
·
View note
Text
TikTok parent company creates KubeAdmiral for Kubernetes

While Kubernetes is still the de-facto standard in container orchestration, a lot of people who work on it would agree that it is in fact quite hard and in need of a lot of polishing. Read More. https://www.sify.com/cloud/tiktok-parent-company-creates-kubeadmiral-for-kubernetes/
#KubeAdmiral#TikTok#Kubernetes#Container#PublicCloud#PrivateCloud#KubeFed#ByteDance#Cluster#ContainerOrchestration
0 notes
Text
0 notes
Text
Lens Kubernetes: Simple Cluster Management Dashboard and Monitoring
Lens Kubernetes: Simple Cluster Management Dashboard and Monitoring #homelab #kubernetes #KubernetesManagement #LensKubernetesDesktop #KubernetesClusterManagement #MultiClusterManagement #KubernetesSecurityFeatures #KubernetesUI #kubernetesmonitoring
Kubernetes is a well-known container orchestration platform. It allows admins and organizations to operate their containers and support modern applications in the enterprise. Kubernetes management is not for the “faint of heart.” It requires the right skill set and tools. Lens Kubernetes desktop is an app that enables managing Kubernetes clusters on Windows and Linux devices. Table of…

View On WordPress
#Kubernetes cluster management#Kubernetes collaboration tools#Kubernetes management#Kubernetes performance improvements#Kubernetes real-time monitoring#Kubernetes security features#Kubernetes user interface#Lens Kubernetes 2023.10#Lens Kubernetes Desktop#multi-cluster management
0 notes
Text
Kubernetes Tutorials | Waytoeasylearn
Learn how to become a Certified Kubernetes Administrator (CKA) with this all-in-one Kubernetes course. It is suitable for complete beginners as well as experienced DevOps engineers. This practical, hands-on class will teach you how to understand Kubernetes architecture, deploy and manage applications, scale services, troubleshoot issues, and perform admin tasks. It covers everything you need to confidently pass the CKA exam and run containerized apps in production.
Learn Kubernetes the easy way! 🚀 Best tutorials at Waytoeasylearn for mastering Kubernetes and cloud computing efficiently.➡️ Learn Now

Whether you are studying for the CKA exam or want to become a Kubernetes expert, this course offers step-by-step lessons, real-life examples, and labs focused on exam topics. You will learn from Kubernetes professionals and gain skills that employers are looking for.
Key Learning Outcomes: Understand Kubernetes architecture, components, and key ideas. Deploy, scale, and manage containerized apps on Kubernetes clusters. Learn to use kubectl, YAML files, and troubleshoot clusters. Get familiar with pods, services, deployments, volumes, namespaces, and RBAC. Set up and run production-ready Kubernetes clusters using kubeadm. Explore advanced topics like rolling updates, autoscaling, and networking. Build confidence with real-world labs and practice exams. Prepare for the CKA exam with helpful tips, checklists, and practice scenarios.
Who Should Take This Course: Aspiring CKA candidates. DevOps engineers, cloud engineers, and system admins. Software developers moving into cloud-native work. Anyone who wants to master Kubernetes for real jobs.
1 note
·
View note
Text
#spotify#kubernetes cluster setup#kubernetes#kubernetes cluster#kubernetes interview questions#kubernetes installation
0 notes
Text
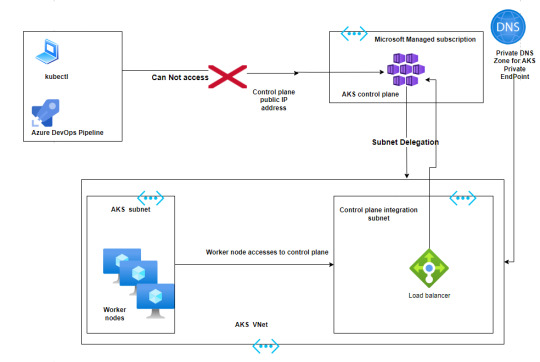
Best practices to deploy Azure Kubernetes services in a Production environment
Azure Kubernetes Service (AKS) has emerged as a leading container orchestration service, offering a plethora of features that streamline the deployment, management, and scaling of containerized applications.
Azure Kubernetes Service (AKS) has emerged as a leading container orchestration service, offering a plethora of features that streamline the deployment, management, and scaling of containerized applications. One of the standout aspects of AKS is its flexibility in offering both public and private clusters, as well as the powerful VNet integrations. In this guide, we’ll delve deep into these…
View On WordPress
0 notes
Text
Kubernetes Admins Warned to Patch Clusters Against New RCE Vulns
Two new high-severity Kubernetes vulnerabilities leave all Windows endpoints on an unpatched cluster open to remote code execution (RCE) with system privileges. Akamai has released a new report flagging the two Kubernetes vulnerabilities, and urged system administrators to take immediate steps to mitigate. The find was built on previous research into Windows nodes vulnerability CVE-2023-3676…
View On WordPress
0 notes